The Next Generation of Oracles

In 2021 the DeFi ecosystem exploded in size with the new protocols covered in various news portals. Financial data feeds are the foundation for projects offering decentralised products like synthetics or insurance. However, the real potential of Web 3.0 is still constrained by the lack of more diverse data types. That’s where RedStone Oracles bring the change with its unique approach of storing non-standard data on Arweave and delivering it to all EVM-compatible chains.
At their core, oracles are middleware that enables the communication between blockchains and off-chain systems such as data providers, cloud providers, IoT devices and payment systems.
Smart contracts on various blockchains, including Ethereum, can use data delivered by an oracle to make decisions whether to execute an agreement or command. Therefore, platforms and businesses utilising smart contracts rely directly on oracles for data feeds from the outside world. Examples of data collected might be the amount of rainfall in a certain area or the number of votes received by a political party.
But centralised and third-party oracles are not in-line with the values of blockchain technology and decentralisation. The external data is not deterministic and fully synchronised, which makes it extremely difficult to reach a consensus between nodes. Moreover, the risk associated with directly accessing an insecure external environment is for many too big to take. Herein lies what is commonly referred to as The Oracle Problem.
The Oracle Problem
Promising decentralisation, blockchain networks do not communicate with the outside world directly as they, by their very nature, have been designed to act independently of intermediary involvement in an isolated manner. Blockchains form a consensus to execute agreements or commands using data that is stored on their ledger, all of which is validated using nodes across distributed networks.
The decentralised nature of blockchains prevents them from pulling in or pushing out data from or to any external system as a built-in functionality.
Blockchains nodes must be kept in isolated sandboxes and as such cannot directly access traditional services or generate data in-house. Without this data, they cannot execute such contracts as deciding the results for insurance policy payouts, determining financial settlements, knowing when to release or settle payments — in other words a specific blockchain is helpless in decisions that are dependent on data from outside of its own infrastructure. All nodes must also operate in the same, predictable, deterministic environment.
Early Attempts
During the early days of blockchain, there was a distinct lack of standards and market leaders. This “wild west” landscape saw almost every protocol creating its own proprietary oracle solution. However, building an oracle is not a trivial task, and home-made oracles turned out to be vulnerable which ended with many hacks. Some of these hacks were far from low profile, with millions of dollars being stolen or lost due to poor practice or human error.
Compound seems had an oracle attack via Coinbase Pro. Nearly $90M of liquidation. pic.twitter.com/ptZsj3X8kf
— Marlboroxu (@marlboroxu) November 26, 2020
As exploits continued, protocol users started migrating towards professional solutions allowing market leaders to grow their shares.
Another early attempt at finding a solution came in the form of a “two phase approach”:
- A contract submits a request for data to an Oracle Service;
- An Oracle Service sends back a response with data.
This simple and flexible solution was pioneered by Oraclize (now Provable) and Chainlink as Basic Request Pattern, but the main disadvantage of this approach is that the contract cannot access data immediately as it requires two separate transactions; this kills usability as the client needs to wait until the data comes to a contract to see the result of an action.
A bigger problem, on top of that, is that fetching data is not atomic — meaning, not in a single transaction. As a result, an Oracle has to synchronise multiple contracts, which is complex, slow and ultimately kills interoperability.
Today’s State of Play
Currently, the most popular approach taken by blockchains in an attempt to address the aforementioned issues is to persist all data directly on-chain, so that the information is available in the context of a single transaction. Protocols have also formed syndicates around the most popular oracles using common standardised configuration.
However, high maintenance costs of this approach mean that storing data directly on-chain is extremely expensive. On a historically busy day, with a daily average 500gwei Gas price, a single transaction may cost above $100, so if we persist every 10m across 30 sources, the daily bill will be more than $400k per one token.
Ethereum in particular was never designed to be a storage network. As Oracles cannot “pause” feeding data, they have to just face transaction costs of a network they are based at.
Ethereum by its design, favours low-latency computation and heavily penalises any input/output operations such as storage. These costs force protocols to pull together the funding which means that they agree to use the same configuration and cannot tailor data to their needs. It is currently only possible to support a small number of tokens with such high operating costs, meaning less popular tokens are excluded from oracle support.
Despite facing scalability and cost obstacles the Oracle Market Cap is valued at about $14 Billion as of January 2022 (according to Coingecko). With an expanding DeFi and crypto industry this number is only going to surge in the near future, so the need for diverse and reliable data will be growing.
Introducing RedStone
RedStone looks to mitigate the presented issues faced by blockchain projects by offering flexible and affordable oracle solutions. The ecosystem has changed dramatically over the last months and current DeFi protocols require more data delivered at lower latency; RedStone offers a radically different design of Oracles catering for the needs of modern Defi protocols.

1/ Affordable Storage
RedStone leverages a new generation of blockchain storage thanks to Arweave, which was designed to keep large amounts of data at a fraction of the costs of chains like Ethereum. As of December 2021 storing 1GB on Arweave would cost $35, while on Ethereum: 1.7M$. Low operating costs allow us to process more data with a higher update frequency.
2/ On demand fetching
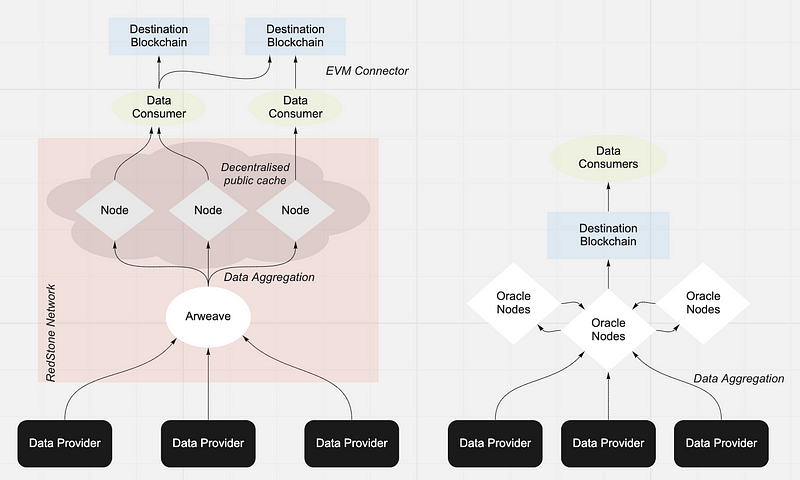
At RedStone innovation comes from our approach of delivering feeds to various chains. We do not simply upload information on blockchain every couple of minutes as the majority of Oracles do. Instead, our idea is to store data on Arweave, while a network of nodes and partners (such as Streamr) makes them available to DeFi projects — in a form of decentralised public cache.
On top of that, EVM-Connector enables to inject this data to the destination chain only when it’s needed. The signature ensuring integrity is attached to the transaction which requires this data, similar to metatransaction. The chart below shows simplified architecture of RedStone data ecosystem (left) and standard Oracle architecture for reference (right).
3/ Flexible Data Streams
The capacity to process more data creates an opportunity for multiple data providers to enter the blockchain ecosystem. Each of them may apply different aggregation rules offering services tailored to the needs of DeFi protocols. A concrete example of this is that a lending pool requires time-averaged data not to liquidate users for a price flash-movement, however a synthetic dex or a margin-trading protocol will be interested to receive the most up to date information.
RedStone can source various types of data — we’re not limited to price data for assets only.
Currently, there are underserved areas in the Web3 space, such as data related to NFT, gaming, insurance, sports statistics, green bonds or even credit scoring. Our focus is to fill these niches with customisable and secure data feeds. RedStone can source various types of data — we’re not limited to price data for assets only. Technically, it is already possible to add other sources to our Oracles. First, we would like to review suggestions of use cases from developers and the community to decide what type of data would be the most useful and enable us to create innovative protocols. Once we see partners with requests for any specific type of data we’ll start working on an implementation. At the same time, becoming a data provider is simple and fully automated, as it is executed via RedStone Contracts. Hence, the whole process is transparent and truly decentralised.
4/ Data Integrity
Allowing multiple data providers generates a need to curate them and select the most reliable ones, hence data providers need to stake RedStone tokens as collateral ensuring that they will keep operating and providing high quality data. RedStone also keeps a full record of the provider’s activity that will be permanently available on the Arweave chain so anyone could question a data feed and receive a part of that collateral in case the data is misrepresented.
The logic that governs dispute resolution is powered by the ArGue protocol based on Schelling point consensus that will be described in detail in a separate post.
5/ Cross-Chain Oracle Solutions
RedStone’s data is cryptographically signed by providers and might be verified on any chain that supports basic cryptographic primitives. As a result, our logic abstracts storage from usage; although the data at RedStone is persisted on the Arweave chain, it could be used with any other blockchain.
When it comes to blockchains, our first choices are EVM (Ethereum Virtual Machine) compatible chains like Ethereum, Celo, Polygon and Avalanche. As of December 2021, over 75% of the whole Total Value Locked (TVL) is based on EVM chains. Our team has invested a lot of resources into maximising the efficiency of data transmission, reaching a point where importing and verifying data could be cheaper than a single read from the EVM storage.
In the future we plan to offer solutions across all major blockchains as part of our deliverables — becoming chain agnostic Oracles of the new generation.
What Are We Doing Now?
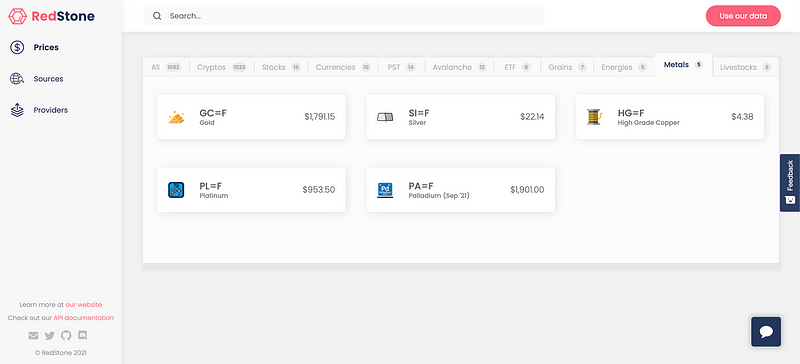
RedStone already fetches data related to more than 1000 assets including crypto tokens, stocks, currencies and commodities. You can check out more on our WebApp.
Data is served by providers that aggregate the information from more than 50 external sources. We have been working hard on optimising, testing and documenting our EVM-Connector technology for importing data to any EVM network. Our proof of concept application for synthetic assets platform uses this technology to connects data to the Ethereum network. You can check that out on our GitHub.
What’s Coming Next?
Our dedicated team works constantly on developing further functionalities and possibilities of RedStone’s infrastructure. Currently, we are working on connecting more data sources and onboarding next providers (if you want to become one of them, fill out this form). Armed with a pipeline of projects that are willing to pilot the solution with us, we’ll be presenting the use cases in the series of blog posts in the coming weeks. You can also check out the AMA session on Arweave News for some more information about RedStone.
We will soon release our token with an incentivisation programme for early adopters, but as for now you can keep up to date with RedStone developments by following us on Twitter and joining our Discord community. We look forward to answering your questions in the comment section below or on RedStone’s Discord channel. If you like what we do leave your 50 claps here!
We’re constantly looking for young talents and seasoned developers. If you’re a top player looking for challenges, write to us and join on a mission to build a data ecosystem for DeFi & Web3 revolution!
RedStone Team